深度学习框架
关于Tensor
pytorch的Tensor和numpy的ndarray的区别是什么
- https://blog.csdn.net/DeepLearning_/article/details/127677006
- https://www.zhihu.com/question/598278407/answer/3573288190
需要计算梯度的Tensor和不需要计算梯度的Tensor的主要区别
| 特性 | 有grad属性(requires_grad=True) | 没有grad属性(requires_grad=False) |
|---|---|---|
| 计算图跟踪 | 跟踪所有运算,构建计算图 | 不跟踪运算,不构建计算图 |
| 内存消耗 | 较高(存储中间结果) | 较低 |
| 计算速度 | 较慢 | 较快 |
| 反向传播 | 支持 | 不支持 |
| 应用场景 | 模型参数、需要优化的变量 | 输入数据、推理阶段、固定参数 |
| numpy转换 | 需要先detach()或使用no_grad() | 可以直接转换 |
补充
定义在__init__里面的模块对应参数的Tensor的requires_grad属性默认都是True,相关运算产生的结果比如
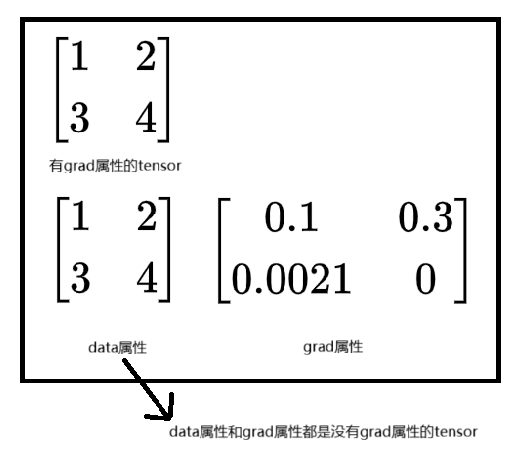 有grad属性的Tensor的结构
有grad属性的Tensor的结构
关于DataLoader
DataLoader设置num_worker出现RuntimeErro
在windows系统下出现这种错误的原因参考:https://blog.csdn.net/qq_64431512/article/details/136489847 ,有两种解决措施:
- 将trainning cycle封装成一个函数
- 将trainning cycle写到
if __name__ == '__main__'的下面
当样本量不能整除batch_size时DataLoder的行为
当数据总量(num_samples)不能被批次大小(batch_size)整除时,DataLoader 的行为取决于你设置的 drop_last 参数。当 drop_last=True 时,DataLoader 会丢弃最后一个不完整的批次。它会创建一个数量为 num_samples // batch_size 的完整批次迭代器。最后剩下的那些不足以组成一个完整批次的数据会被直接忽略,不参与训练。当 drop_last=False 时,DataLoader 会保留最后一个不完整的批次。
常用的损失和激活函数
常用的损失
- 平方损失(Square Error):
- 交叉熵损失(Cross Entropy):两个离散分布
之间的差异可以使用交叉熵衡量,交叉熵越大说明两个分布的差异越大 ,pytorch中实现交叉熵损失有三个类——BCELoss,CrossEntropyLoss,NLLLoss。其中BCELoss算的是两个二项分布之间的交叉熵,CrossEntropyLoss算的是一个向量,经过softmax函数处理后得到的分布与某个分布的交叉熵,而NLLLoss算的是一个取了对数的分布(实际已经不再是分布了,不满足分布的规范性)与某个分布的做内积再取负数
常用激活函数
- logistic函数:是sigmoid函数的一种,由于是最常用的sigmoid函数,所以pytorch里面的sigmoid就是指的logistic函数。
- relu函数:小于0映射到0,大于零取自身
- softmax函数:就是先指数运算,然后归一化,
torchvision包是干嘛的
Torchvision 是 PyTorch 项目中的一个核心库,专门为计算机视觉任务而设计,你装pytorch的时候除了torch库就还附带了它。它提供了三大类核心功能,极大地简化了构建和训练计算机视觉模型的过程:
- 流行的数据集:方便地加载和使用常见的数据集。
- 模型架构:预定义好的经典和前沿的模型。
- 图像变换工具:用于数据预处理和数据增强的强大工具。可以把它看作是 PyTorch 在计算机视觉领域官方工具包。
常见网络结构的实现
CNN
如果你要用DNN处理一张100x100像素的彩色图片。输入层就需要100x100x3=30,000个神经元。假设第一个隐藏层有1000个神经元,那么仅这一层就会有30,000 * 1000=30,000,000个权重参数!除了计算量大,它还会忽略图像的空间结构。对于DNN来说,输入就是把所有像素点排成一个长向量,因为全连接层的输入张量只能是二维的,形状是(batch_size,feature_num),它完全不知道哪个像素和哪个像素在空间上是相邻的。而CNN通过局部感知、权值共享和池化,以一种更智能、更高效的方式利用了图像数据的内在规律,从而在性能、效率和鲁棒性上全面碾压全连接神经网络。实际上基础的CNN并不复杂,就是对输入的位图先做一系列的卷积运算和池化运算,然后改变形状再接到全连接层里面。所以,搭建CNN最关键的就是搞清楚卷积运算和池化运算是怎么做的,做完这些操作之后输出的形状是什么样子。

卷积层和池化层的作用
- 卷积层 就像公司里的 “一线员工”,负责从原始数据中主动寻找和提取具体特征(比如边缘、角点、纹理)
- 池化层 就像 “中层管理者”,负责对员工提取到的海量信息进行汇总、压缩和精简,保留最关键的部分,并传递给下一级
用pytorch搭建如下结构的CNN网络:
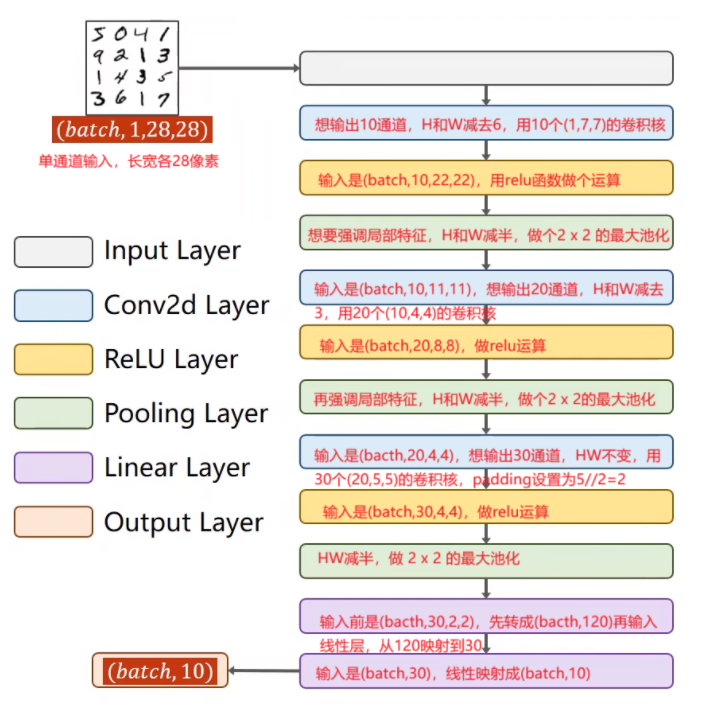
使用GPU训练CNN做手写数字识别#!/usr/bin/env python # -*- coding: utf-8 -*- # @Date : 2025-10-27 20:04:17 # @Author : syuansheng (Dalian Maritime University) """ 设计一个CNN用于手写数字的识别 """ import torch from torch.utils.data import DataLoader from torchvision.transforms import Compose # 将几种转换按顺序拼接到一起,形成一个pipeline from torchvision.transforms import ToTensor # Converts a PIL Image or numpy.ndarray (H x W x C) in the range [0, 255] to a torch.FloatTensor of shape (C x H x W) in the range [0.0, 1.0],为什么要设计从HWC转换成CHW,因为这种形式卷积效率更高 from torchvision.transforms import Normalize # Normalize a tensor image with mean and standard deviation.Given mean: ``(mean[1],...,mean[n])`` and std: ``(std[1],..,std[n])`` for ``n`` channels from torchvision.datasets import MNIST # 基于MNIST数据集,集成抽象基类Dataset实现的数据集类 device = torch.device("cuda:0" if torch.cuda.is_available() else 'cpu') # 检查gpu设备是否可用,如果可用获取改设备 # 1. 准备数据 # 先构造一下转换函数,把图像hwc转为chw,然后像数值映射到0-1区间,并对每个通道做标准化处理,已知通道1的均值和标准差为0.1307,0.3081 transforms = Compose([ ToTensor(), Normalize((0.1307,),(0.3081,)) ]) # 创建数据集对象 train_dataset = MNIST( './mnist/', train = True, # 读取MNIST问题的训练数据集 download = True, # 从网络上下载 transform = transforms # 对样本做什么转换 ) test_dataset = MNIST( './mnist/', train = False, # 读取MNIST问题的训练数据集 download = True, # 从网络上下载 transform = transforms # 对样本做什么转换 ) # 创建batch的加载器 batch_size = 64 # 每个batch有多少样本,对于这个问题就是有多少张图片 train_loader = DataLoader(train_dataset,shuffle=True,batch_size=batch_size) test_loader = DataLoader(test_dataset,shuffle=False,batch_size=batch_size) # 2. 构造模型 class CNN(torch.nn.Module): def __init__(self): # 继承torch.nn.Module,实现requires_grad=True的Tensor的管理 super(CNN,self).__init__() # 所有包含requires_grad=True张量的模块都得在这实例化,requires_grad=False的不强求 self.relu = torch.nn.ReLU() self.pool = torch.nn.MaxPool2d(kernel_size=2) self.conv2d_1 = torch.nn.Conv2d(in_channels=1,out_channels=10,kernel_size=(7,7)) self.conv2d_2 = torch.nn.Conv2d(in_channels=10,out_channels=20,kernel_size=(4,4)) self.conv2d_3 = torch.nn.Conv2d(in_channels=20,out_channels=30,kernel_size=(5,5),padding=2) self.linear_120_to_30 = torch.nn.Linear(120,30) self.linear_30_t0_10 = torch.nn.Linear(30,10) def forward(self,batch_x): # 重载前向船舶 batch_x = self.pool(self.relu(self.conv2d_1(batch_x))) batch_x = self.pool(self.relu(self.conv2d_2(batch_x))) batch_x = self.pool(self.relu(self.conv2d_3(batch_x))) # 输入全连接层之前先展平 flatten_batch_x = batch_x.view(batch_x.size(0),-1) # 除了0dim,其它dim展平 flatten_batch_x = self.linear_120_to_30(flatten_batch_x) flatten_batch_x = self.linear_30_t0_10(flatten_batch_x) return flatten_batch_x cnn_model = CNN() cnn_model.to(device) # 模型迁移到gpu上 # 3. 构造损失函数和优化器 criterion = torch.nn.CrossEntropyLoss(size_average=True,reduce=True) optimizer = torch.optim.SGD(cnn_model.parameters(),lr=0.01) # 4. 训练cycle def train(epoch): # 定义一个epoch的训练,一个epoch的定义是所有训练数据完成一次forward和backward for iteration,(x_batch,y_batch) in enumerate(train_loader): x_batch,y_batch = x_batch.to(device),y_batch.to(device) # 迁移到gpu上 # 前向 y_pred = cnn_model(x_batch) loss = criterion(y_pred,y_batch) # 反向 loss.backward() if iteration % 99 == 0: # 每100个batch打印一次当前batch上的损失 print("epoch:{}/iteration:{} with loss {}".format(epoch,iteration,loss.data.item())) # 更新 optimizer.step() optimizer.zero_grad() def test(): correct_num = 0 # 测试集预测正确的数量 total_num = 0 # 测试集样本总数 # 测试集不需要计算梯度,把梯度计算关闭,注意forward的时候就开始计算局部梯度了!!! with torch.no_grad(): for _,(batch_x,batch_y) in enumerate(test_loader): batch_x,batch_y = batch_x.to(device),batch_y.to(device) # 迁移到gpu上 y_pred = cnn_model(batch_x) # 进行预测,注意最后一层是线性的,没有做softmax y_pred = torch.nn.functional.softmax(y_pred,dim=1) # 沿着张量dim=1的方向做softmax _,idx = torch.max(y_pred,dim=1) # 获取每行最大值及其索引 correct_num += (batch_y==idx).sum().item() # 这一批预测正确的样本数 total_num += batch_y.size(0) print("accuracy={}".format(correct_num/total_num)) if __name__ == '__main__': for epoch in range(300): train(epoch) test()
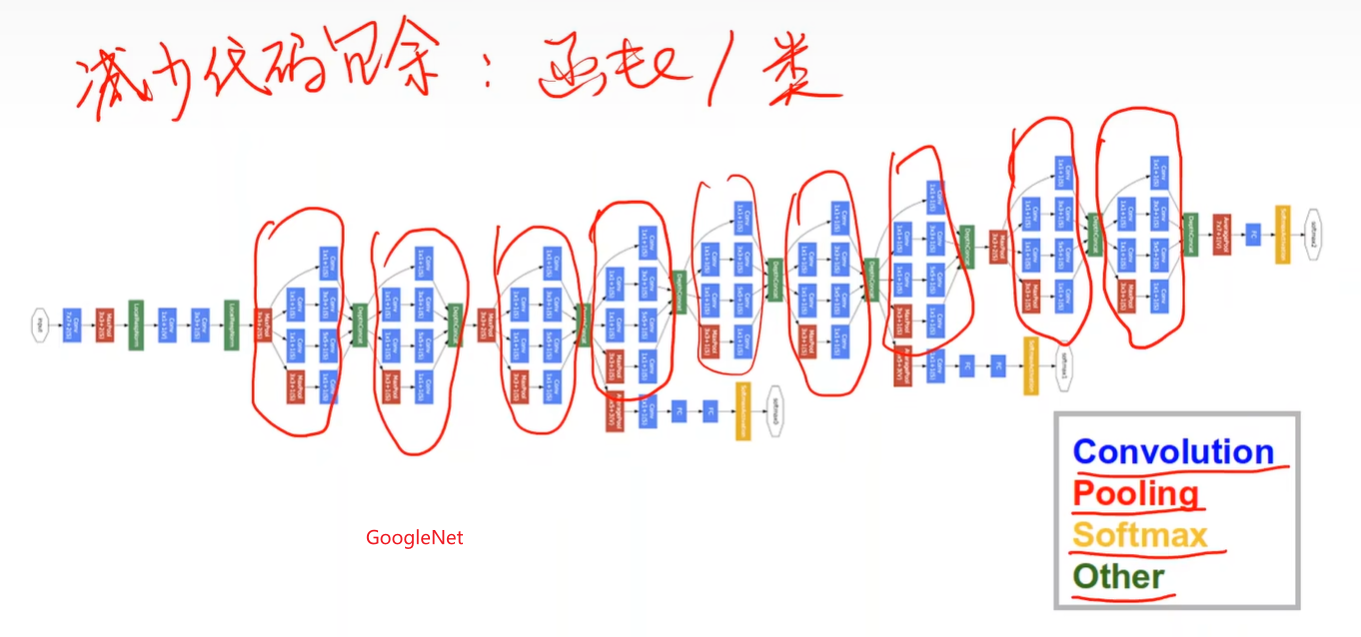
实现GoogleNet的Inception模块
Google Net 是谷歌研究团队在2014年提出的一种深度卷积神经网络结构,并在当年的 ImageNet Large Scale Visual Recognition Challenge (ILSVRC)中取得了冠军。它的出现是深度学习发展史上的一个里程碑,其核心思想是在增加网络深度和宽度的同时,高效地控制计算成本和参数量。Google Net 的灵魂是其 Inception 架构。它的设计灵感来自一个朴素的 idea:为什么不让网络自己“选择”合适的卷积核大小呢?
|
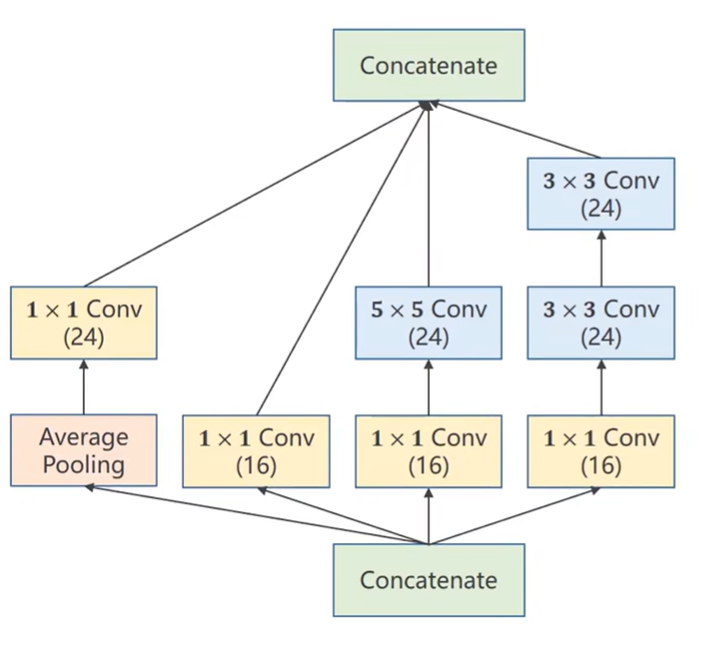
|
一张图片中,不同尺度的信息可能都很重要。有的特征需要大感受野来捕获(如全局轮廓),有的则需要小感受野来捕获精细细节。最初的设想是在同一层上并行地使用多个不同大小的卷积核(如 1x1, 3x3, 5x5)和池化操作,然后将它们的输出结果在通道维度上拼接起来。这样,下一层就可以同时接收到不同尺度的特征信息。然而,上面的“朴素”想法存在一个严重问题:计算量巨大。尤其是 5x5 卷积,其计算成本非常高。解决思路是使用
- 1x1卷积直接提取特征。
- 3x3卷积前先用 1x1 卷积降维。
- 5x5卷积前先用 1x1 卷积降维。
- 3x3最大池化后也用 1x1 卷积来调整通道数,防止池化后的通道数过多。这种设计使得模块既能捕捉多尺度特征,又保证了计算效率。
Inception模块实现的关键就是注意保证沿着channel方向拼接的各个块需要保证height和width一致,搭建一个包含Inception模块的卷积神经网络用于手写数字识别:
带inception模块的CNN#!/usr/bin/env python # -*- coding: utf-8 -*- # @Date : 2025-11-18 10:26:22 # @Author : syuansheng (Dalian Maritime University) import torch from torch.utils.data import DataLoader # 把数据拆分位批次 from torchvision.transforms import Compose # 将几种转换按顺序拼接到一起,形成一个pipeline from torchvision.transforms import ToTensor # Converts a PIL Image or numpy.ndarray (H x W x C) in the range [0, 255] to a torch.FloatTensor of shape (C x H x W) in the range [0.0, 1.0],为什么要设计从HWC转换成CHW,因为这种形式卷积效率更高 from torchvision.transforms import Normalize # Normalize a tensor image with mean and standard deviation.Given mean: ``(mean[1],...,mean[n])`` and std: ``(std[1],..,std[n])`` for ``n`` channels from torchvision.datasets import MNIST # 基于MNIST数据集,集成抽象基类Dataset实现的数据集类 device = torch.device("cuda:0" if torch.cuda.is_available() else 'cpu') # 检查gpu设备是否可用,如果可用获取改设备 # 1. 准备数据 # 先构造一下转换函数,把图像hwc转为chw,然后像数值映射到0-1区间,并对每个通道做标准化处理,已知通道1的均值和标准差为0.1307,0.3081 transforms = Compose([ ToTensor(), Normalize((0.1307,),(0.3081,)) ]) # 创建数据集对象 train_dataset = MNIST( './mnist/', train = True, # 读取MNIST问题的训练数据集 download = True, # 从网络上下载 transform = transforms # 对样本做什么转换 ) test_dataset = MNIST( './mnist/', train = False, # 读取MNIST问题的训练数据集 download = True, # 从网络上下载 transform = transforms # 对样本做什么转换 ) # 创建batch的加载器 batch_size = 64 # 每个batch有多少样本,对于这个问题就是有多少张图片 train_loader = DataLoader(train_dataset,shuffle=True,batch_size=batch_size) test_loader = DataLoader(test_dataset,shuffle=False,batch_size=batch_size) # 2. 构造模型 class Inception(torch.nn.Module): """ 实现GoogleNet的inception模块 """ def __init__(self,input_channel:int): super(Inception,self).__init__() # 继承torch.nn.Module,实现requires_grad=True的Tensor的管理 self.conv2d_16_1_1 = torch.nn.Conv2d(in_channels=input_channel,out_channels=16,kernel_size=(1,1)) self.conv2d_24_1_1 = torch.nn.Conv2d(in_channels=input_channel,out_channels=24,kernel_size=(1,1)) self.conv2d_24_3_3_a = torch.nn.Conv2d(in_channels=16,out_channels=24,kernel_size=(3,3),padding=1) self.conv2d_24_3_3_b = torch.nn.Conv2d(in_channels=24,out_channels=24,kernel_size=(3,3),padding=1) self.conv2d_24_5_5 = torch.nn.Conv2d(in_channels=16,out_channels=24,kernel_size=(5,5),padding=2) # 参数padding和stride的设置都是为了保证输出的宽度和高度不变 def forward(self,batch_x): # 重载torch.nn.Module的前向船舶 batch_x_1 = torch.nn.functional.avg_pool2d(batch_x,kernel_size=3,stride=1,padding=1) batch_x_1 = self.conv2d_24_1_1(batch_x_1) batch_x_2 = self.conv2d_16_1_1(batch_x) batch_x_3 = self.conv2d_16_1_1(batch_x) batch_x_3 = self.conv2d_24_5_5(batch_x_3) batch_x_4 = self.conv2d_16_1_1(batch_x) batch_x_4 = self.conv2d_24_3_3_a(batch_x_4) batch_x_4 = self.conv2d_24_3_3_b(batch_x_4) outputs = [batch_x_1,batch_x_2,batch_x_3,batch_x_4] return torch.cat(outputs,dim=1) # (batch,c,h,w) 沿着通道方向把张量拼接起来 class CNNWithInception(torch.nn.Module): """ 包含Inception模块的卷积神经网络,关键就是把各层输入输出的形状搞清楚,这样你的模型一定能跑起来 """ def __init__(self): super(CNNWithInception,self).__init__()# 继承torch.nn.Module,实现requires_grad=True的Tensor的管理 self.conv2d_1 = torch.nn.Conv2d(in_channels=1,out_channels=10,kernel_size=(5,5)) self.conv2d_2 = torch.nn.Conv2d(in_channels=88,out_channels=20,kernel_size=(5,5)) self.inception1 = Inception(input_channel=10) self.inception2 = Inception(input_channel=20) self.mp = torch.nn.MaxPool2d(2) self.fc = torch.nn.Linear(1408,10) def forward(self,batch_x): batch_size = batch_x.size(0) batch_x = torch.nn.functional.relu(self.mp(self.conv2d_1(batch_x))) batch_x = self.inception1(batch_x) batch_x = torch.nn.functional.relu(self.mp(self.conv2d_2(batch_x))) batch_x = self.inception2(batch_x) batch_x = batch_x.view(batch_size,-1) return self.fc(batch_x) # 最后连到全连接层 model = CNNWithInception() model.to(device) # 模型迁移到gpu上 # 3. 构造损失函数和优化器 criterion = torch.nn.CrossEntropyLoss(size_average=True,reduce=True) optimizer = torch.optim.SGD(model.parameters(),lr=0.01) # 4. 训练cycle def train(epoch): # 定义一个epoch的训练,一个epoch的定义是所有训练数据完成一次forward和backward for iteration,(x_batch,y_batch) in enumerate(train_loader): x_batch,y_batch = x_batch.to(device),y_batch.to(device) # 迁移到gpu上 # 前向 y_pred = model(x_batch) loss = criterion(y_pred,y_batch) # 反向 loss.backward() if iteration % 99 == 0: # 每100个batch打印一次当前batch上的损失 print("epoch:{}/iteration:{} with loss {}".format(epoch,iteration,loss.data.item())) # 更新 optimizer.step() optimizer.zero_grad() def test(): correct_num = 0 # 测试集预测正确的数量 total_num = 0 # 测试集样本总数 # 测试集不需要计算梯度,把梯度计算关闭,注意forward的时候就开始计算局部梯度了!!! with torch.no_grad(): for _,(batch_x,batch_y) in enumerate(test_loader): batch_x,batch_y = batch_x.to(device),batch_y.to(device) # 迁移到gpu上 y_pred = model(batch_x) # 进行预测,注意最后一层是线性的,没有做softmax y_pred = torch.nn.functional.softmax(y_pred,dim=1) # 沿着张量dim=1的方向做softmax _,idx = torch.max(y_pred,dim=1) # 获取每行最大值及其索引 correct_num += (batch_y==idx).sum().item() # 这一批预测正确的样本数 total_num += batch_y.size(0) print("accuracy={}".format(correct_num/total_num)) if __name__ == '__main__': for epoch in range(300): train(epoch) test()
 微信
微信