最优化理论与方法初探
最优化问题分类
- 无约束/约束优化
- 线性/非线性优化
- 连续/离散优化
- 动态规划
- 不确定性优化(随机优化/鲁棒优化)
随机规划和鲁棒规划在处理参数不确定问题时的区别
随机规划和鲁棒优化都是运筹优化中比较高阶的内容。二者都是考虑不确定情形下的数学规划,但是两者又有不同。随机规划旨在优化不确定情形下的目标函数的期望等,比如总收益的期望值等。但是鲁棒优化致力于使得最坏的情况最好。所以相比而言,基本的鲁棒优化获得的结果会比较保守。
凸集
定义
凸集:对于集合
- 超平面
- 半空间
- 多面体
- 球心为
半径为 的球 - 记
为 维向量,其中 是前 维分量构成的向量, 是第 维的标量,满足\{(x,t)|\left|x \right|\le t\}的 所张成的空间我们称为二阶锥。 - 半定矩阵锥:记
为实对称矩阵,则满足 的 中分量形成的图形称为半定矩阵锥。
仿射组合:如果线性组合的组合系数和为1,则称该线性组合为仿射组合。
非负组合:如果线性组合的组合系数非负,则称该线性组合为非负组合。
凸组合:如果线性组合的组合系数非负且和为1,则称该线性组合为凸组合。
凸包:包含集合
性质
保证集合凸性的运算:设
仍然是凸集。 是凸集。 - 仿射变换不改变集合的凸性,设
是仿射函数,即 ,则 仍然是凸集。
投影定理:设
- 记
是 到 距离最近的一点,那么这一点是唯一的,称为 到 的投影点。 是 到 投影点的充要条件是 。
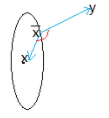 Fig1. 投影点示意图
Fig1. 投影点示意图
凸集分离定理:设
支撑超平面定理:设
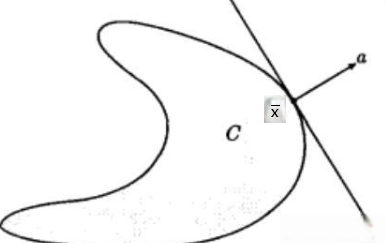 Fig2. 支撑超平面示意图
Fig2. 支撑超平面示意图
凸函数
定义
凸函数:设
几何意义
在二维情况,凸函数
- 线性函数
。 - 当
半正定时形成的二次函数 。 - 最小二乘函数,即线性函数二范数的平方
。 - p范数,当
时, 。
性质
凸函数的充要条件:
- 设
是凸函数 ,一元函数 也是凸函数。 - 设
是定义在 上的凸函数 始终在它的切平面上方,即 。 - 设
非空开凸集,则 是定义在 上凸函数 。
保证函数凸性的运算:
- 设
是凸函数, ,则透视函数 也是凸函数。 - 凸函数的非负组合还是凸函数。
- 任意数量个凸函数求最大的函数
还是凸函数。
凸函数和凸集的关系:凸函数
凸优化
定义
凸优化问题
当目标函数
- LP(Linear programming)
- QP(Quadratic programming)
- QCQP(Quadratically constraint Quadratic programming)
- SOCP(Second-Order cone programming),这个在鲁棒优化里面会常遇到
- SDP(Semi-definite programming)
凸优化问题的性质
- 凸优化的局部最优解也是全局最优解。
是上述凸优化问题最优解 ,即不管往哪个方向调整 ,目标函数值都会增大。
无约束优化
最优性条件
考虑最优化问题
- 若函数
是凸函数,则 是最优解 。这个用凸优化问题的最优性条件易得。 - 对于一般函数
, 是最优解的必要条件是 ;充分条件是 。这个证明要用到反证法和多元函数的泰勒展开。
基于线搜索的迭代下降算法
用于求解无约束优化问题的算法是迭代下降算法,基本思路是给定初始点
- 线搜索方法:先找函数在当前位置的下降方向(常用负梯度方向、牛顿方向或共轭梯度方向),然后再确定一个步长。按照下降方向选择上的区别,又可以将线搜索方法分为:
- 坐标轴交替下降法
- 最速下降法
- 牛顿法
- 拟牛顿法
- 共轭梯度法
- 信赖域方法:先确定一个一个区域(之所以叫信赖域是说目标函数再这个小区域的近似是相对准确的),然后再确定下降方向,本节不讨论这个方法。
 Fig3. 基于线性搜索的迭代下降算法步骤
Fig3. 基于线性搜索的迭代下降算法步骤
1维线搜索过程求解
确定步长
- 如果
是凸函数,那么由凸函数的充要条件,一元函数 也是一个凸函数,那么由凸函数的最优性条件,求解 即可。 - 如果
是一般的函数,则又有两种方法:(1) 基于搜索区间的直接搜索法:所谓搜索区间就是指包含 且单谷(即函数 在这个区间先单调减再单调增)的区间。这种方法的思路就是通过特定的策略不断缩小搜索区间,从而最终就能得到 或它的近似值。(2) 非精确线搜索,不追求找到最好的 ,只要求找到的 满足 小于 且这个 不是太小:例如Goldstein准则。
最速下降法

原因那块儿解释的是为什么最速下降算法会出现zigzag现象,就是因为前一个点和后一个点处的负梯度方向是垂直关系。关于矩阵求导可以看张贤达那本书或百度查公式。
以最小化
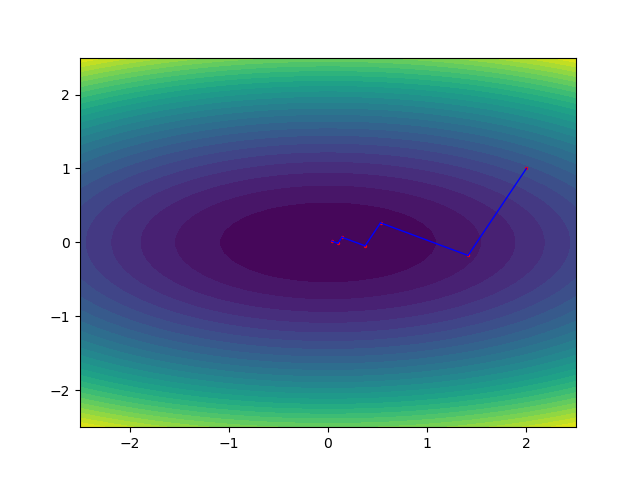
梯度下降算法的zigzag问题#!/usr/bin/env python # -*- coding: utf-8 -*- # @Date : 2025-08-11 20:27:30 # @Author : syuansheng (Dalian Maritime University) """ 实现了最速下降算法,使用min f(x)=0.5x_{1}^{2}+2x_{2}^{2},初始点x^{0}=(2,1)^{T}这个案例探索了 最速下降算法的zigzag现象,及其收敛速度较慢的原因。 """ from numpy import array from numpy.linalg import norm def f(x1,x2): """ 用于测试的凸二次函数 """ return 0.5*x1**2+2*x2**2 def gradf(x1,x2): """ 函数f在(x1,x2)处的梯度 """ return array([x1,4*x2]) def get_best_alpha(x1,x2,d1,d2): """ 由于0.5x_{1}^{2}+2x_{2}^{2}是凸函数,所以最优步长可用最优性条件确定 """ return -(x1*d1+4*x2*d2)/(d1**2+4*d2**2) def gradient_descent(f,gradf,x0,epsilon=0.1): """ 最速下降算法求解函数的极值 Args: f: 待求解的函数 gradf: 待求解函数的梯度 x0: 初始点 epsilon: 容差,控制算法什么时候终止 returns: xlst: 探索郭的点列,xlst[-1]就是“极值点” """ xlst = [x0] while True: print(xlst) # 终止条件设置为梯度基本上是0向量时 if norm(gradf(*xlst[-1])) < epsilon: return xlst else: # 下降方向取负梯度方向 d = -gradf(*xlst[-1]) # 求解1维线搜问题,确定步长 alpha = get_best_alpha(*xlst[-1],*d) xlst.append(xlst[-1]+alpha*d) if __name__ == '__main__': xlst = gradient_descent(f,gradf,x0=array([2,1])) from matplotlib import pyplot as plt from numpy import meshgrid,linspace fig,ax = plt.subplots(figsize = (6.4,4.8)) X1,X2 = meshgrid(linspace(-2.5,2.5,50),linspace(-2.5,2.5,50)) Y = 0.5*X1**2+2*X2**2 ax.contourf(X1,X2,Y,levels=30) # 绘制最速下降算法的探索过程 for x1,x2 in xlst: ax.scatter([x1,],[x2,],color='red',s=2) for i in range(len(xlst)-1): ax.plot([xlst[i][0],xlst[i+1][0]],[xlst[i][1],xlst[i+1][1]],color='blue',lw=1) plt.show()
牛顿法
牛顿法的基本思路是对函数
当
所以牛顿法取

纯牛顿法里面,步长
是直接取1。
二次终止性 (Quadratic Termination) 的精确定义是:当一个优化算法应用于一个n元严格凸二次函数时,能够在有限步内(最多n步)精确收敛到全局最小值点(忽略数值舍入误差),则该算法具有二次终止性。下面还是用最小化
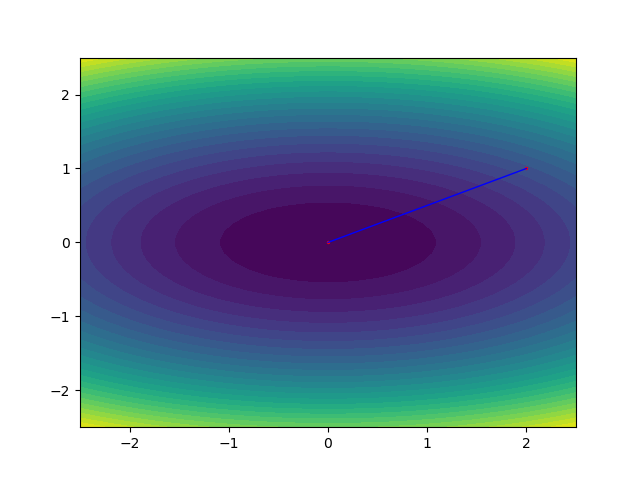
牛顿法具有二次终止性#!/usr/bin/env python # -*- coding: utf-8 -*- # @Date : 2025-08-12 10:26:27 # @Author : syuansheng (Dalian Maritime University) """ 实现了纯牛顿法 """ from numpy import array,dot from numpy.linalg import norm def f(x1,x2): """ 用于测试的凸二次函数 """ return 0.5*x1**2+2*x2**2 def gradf(x1,x2): """ 函数f在(x1,x2)处的梯度 """ return array([x1,4*x2]) def invhessf(x1,x2): """ 函数f在(x1,x2)处的黑塞矩阵的逆矩阵 """ return array([[1,0],[0,1/4]]) def newton(f,gradf,invhessf,x0,epsilon=0.1): """ 牛顿法求解函数的极值 Args: f: 待求解的函数 gradf: 待求解函数的梯度 invhessf: 黑塞矩阵的逆矩阵 x0: 初始点 epsilon: 容差,控制算法什么时候终止 returns: xlst: 探索郭的点列,xlst[-1]就是“极值点” """ xlst = [x0] while True: print(xlst) if norm(gradf(*xlst[-1]))<epsilon: return xlst else: d = - dot(invhessf(*xlst[-1]),gradf(*xlst[-1])) xlst.append(xlst[-1]+d) if __name__ == '__main__': xlst = newton(f,gradf,invhessf,x0=array([2,1])) from matplotlib import pyplot as plt from numpy import meshgrid,linspace fig,ax = plt.subplots(figsize = (6.4,4.8)) X1,X2 = meshgrid(linspace(-2.5,2.5,50),linspace(-2.5,2.5,50)) Y = 0.5*X1**2+2*X2**2 ax.contourf(X1,X2,Y,levels=30) # 绘制牛顿算法的探索过程 for x1,x2 in xlst: ax.scatter([x1,],[x2,],color='red',s=2) for i in range(len(xlst)-1): ax.plot([xlst[i][0],xlst[i+1][0]],[xlst[i][1],xlst[i+1][1]],color='blue',lw=1) plt.show()
为了处理牛顿法存在的问题,可以从步长和下降方向两个方面进行修正。

拟牛顿法
和牛顿法非常像,区别在于对二次函数做近似的时候把
在拟牛顿法中我们期望
记

scipy.optimize模块的minimize函数基本上实现了上述所有算法。使用时注意在传递func之前,如果待优化函数中包含参数,得先用functools的partial函数把参数固定住,传递给func的的函数必须只有x(变向量)这一个参数。
共轭梯度法
这个方法用的下降方向之间式共轭的关系,所以叫做共轭方向法(共轭梯度法是共轭方向法的一种),这个方法理论没看懂,后面补一点矩阵分析的知识再学一遍。

约束优化
一般形式约束优化问题
最优性条件
一阶必要条件KKT条件
设$x^{}
这就是kkt条件,其中前两个式子称为对偶可行性条件(dual feasible)、第三个式子叫做原始可行性条件(primal feasible),最后一个式子叫做互补松弛条件。
关于kkt条件的补充说明
- 如果问题
是凸优化问题,那么kkt条件是最优解的充要条件,可以通过分类讨论求解出最优值点。 - 关于lagrangian乘子,(可证明)它可以用来分析
中约束右端项发生扰动对目标函数的影响,比如所 ,这就说明将第一个约束放宽比放宽第二个约束让目标函数下降的更多(对于Min问题,Max问题就是上升的多)。这个东西实际上就是线性规划里面的影子价格。
kkt条件有什么应用?
- 告诉你一个点是不是最优解(尤其对于凸问题)。
- 如果是最优解,它告诉你这个解是如何由目标函数和约束共同决定的(梯度关系)。
- 告诉你哪些约束真正起到了限制作用(互补松弛),对于lagrangian乘子为0的约束实际上并没有起作用。
- 告诉你改变约束条件会对结果产生多大影响(影子价格)。
- 为计算机找到这个最优解提供了方法和目标(许多求解约束优化问题的数值算法,如序列二次规划、内点法,直接以KKT条件作为算法的终止准则或迭代目标)。
二阶最优性条件
设
若
,则 是 的全局最优解。 若$\nabla^{2} L(x)\succeq 0,\forall x\in S\cap N_{\delta}(x^{})
x^{} (P)$的局部最优解。 若
,则 是 的严格局部最优解。
对偶理论
这块难度好大,没怎么理解,后期学习下点功夫!
考虑如下一般形式的约束优化问题
前面提最优性条件没有
这一项,因为是针对连续优化问题讲的,在对偶理论里面可以考虑离散优化。
写对偶问题的步骤
(1) 写出原问题
(2) 由原问题的拉格朗日函数写出拉格朗日对偶函数,可以注意到当
(3) 去找原问题最好下界的问题就是对偶问题。
弱对偶、强对偶定理和对偶GAP
- 弱:由对偶问题的定义可知,设
分别是原问题和对偶问题的值,则 。 - 强:当
是凸优化问题,且 满足某种约束规范,则 。 - 对偶GAP:
。
对偶问题的基本性质
对偶函数一定是凹函数,所以对偶问题只需要对目标函数稍做变形(转min加负号)就可以转换成凸优化问题。
 微信
微信