决策树分支属性的三种选择方法

决策树算法的核心就是划分属性的选择,按照最优划分属性选择方法的不同可以把决策树算法分为ID3、C4.5和CART算法。本质上来说,决策树的构建过程
就是一个熵减的过程,也就是集合混乱度贬低,纯度变高的过程。要刻画集合的混乱程度,可以使用以下两个公式,这两个公式计算出来的值越小就说明集合的混乱度越低,纯度越高,反之亦反之。记
- 信息熵
- 基尼指数
针对某个特定的属性,他可能有很多取值,我们就可以按照样本在这个属性上取值的不同把集合
上面两个公式去计算它们的混乱程度
话不多说,看一个例子,使用CART(classification and regression tree)算法画出下面这个问题的决策树:

按工作,我们可以把当前集合
按房子,我们可以把当前集合
按信誉,我们可以把当前集合
可以看到对于当前集合
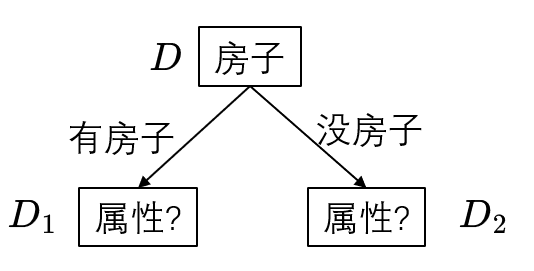
继续使用上面的方法对得到的新集合进行划分即可,不再赘述了,思想就是这个思想。
All articles on this blog are licensed under CC BY-NC-SA 4.0 unless otherwise stated.
 微信
微信